



En este artículo, el analista OSINT y profesor del Curso Avanzado de Analista SOCMINT: Inteligencia de Redes Sociales (Nivel 1) y del Curso de Experto en OSINT: Técnicas de Investigación Online de LISA Institute, Manuel Travezaño, explica cómo se puede obtener información personal de sitios web a través de técnicas como el web scraping y cómo funciona una de las principales herramientas OSINT para hacerlo.
En internet, existen una diversidad de sitios electrónicos que brindan información visual y gráfica que pueda ser leída por cualquier cibernauta con el único fin de informarse de algún evento, noticia o información de relevancia. A los analistas de Inteligencia o analistas tácticos de ciberinteligencia nos es de mucha utilidad obtener también la información adicional que una plataforma web o sitio electrónico puede brindarnos si sabemos cómo hacerlo.
Apoyándonos en la Inteligencia de Fuentes Abiertas (OSINT), Inteligencia de Redes Sociales (SOCMINT) y, sobre todo, en el uso de técnicas de web scraping o raspado de datos podemos acceder a otra información como datos personales, correos electrónicos, números de teléfono, geolocalizaciones, direcciones IP, entre otros, ayudándonos a realizar con éxito nuestras ciberinvestigaciones.
¿Qué es el scraping de datos? ¿Y el web scraping?
Según la empresa de Plataforma unificada de red y de seguridad (Cloudflare), el scraping es una técnica en la cual un programa informático extrae datos del resultado generado por otro programa. El scraping de datos se manifiesta normalmente en el web scraping, el proceso de utilizar una aplicación para extraer información valiosa de un sitio web.
➡️ Te puede interesar: Masterclass | Autoprotección digital para ciberinvestigar de forma segura | LISA Institute
¿Está permitido el web scraping? ¿Es legal?
En este punto nos podemos estar preguntando si recopilar información a través del scraping es legal. En general, la recopilación de información a través del OSINT y SOCMINT o técnicas como el web scraping no es ilegal, siempre y cuando se respeten los derechos de privacidad de las personas naturales y jurídicas y, a su vez, se cumplan las leyes de protección de datos. Esto significa que no se puede recopilar información sin el consentimiento de los individuos o sin una base legal legítima para hacerlo.
Además, en muchos países, la recopilación de información personal a través de las redes sociales y sitios electrónicos puede estar sujeta a regulaciones específicas, como la Ley de Protección de datos de la Unión Europea o la Ley de Privacidad del Consumidor de California. Es importante tener en cuenta que para el uso del web scraping existen limitaciones relacionadas con la información (qué se puede recopilar y qué no) y cómo se puede utilizar. Dependiendo del país o región, puede haber leyes que limiten la recopilación y empleo de información de las redes sociales y sitios electrónicos con fines comerciales o de investigación.
Ahora, conociendo los términos del web scraping, que es básicamente una forma de recopilar datos de páginas web a gran escala de forma muy rápida, y de los límites legales que pueda encontrarse en su uso, podemos decir que, en la actualidad, existen diversas herramientas OSINT y SOCMINT para obtener estos datos a través de esta técnica.

➡️ Te puede interesar: Masterclass | Kit de Herramientas de OSINT y Ciberinvestigación
Uscrapper: la herramienta OSINT para realizar web scraping
Como ejemplo de una herramienta OSINT que permite a los usuarios, extraer diversa información personal de un sitio web mencionamos Uscrapper, una de muchas herramientas que se explican en el Curso Avanzado de Analista SOCMINT: Inteligencia de Redes Sociales (Nivel 1) de LISA Institute. Esta herramienta permite, aprovechando las técnicas de web scraping, extraer de una forma fácil direcciones de correos electrónicos, enlaces a redes sociales del objetivo, nombres de usuarios, geolocalizaciones, números de teléfono, entre otros sitios electrónicos.
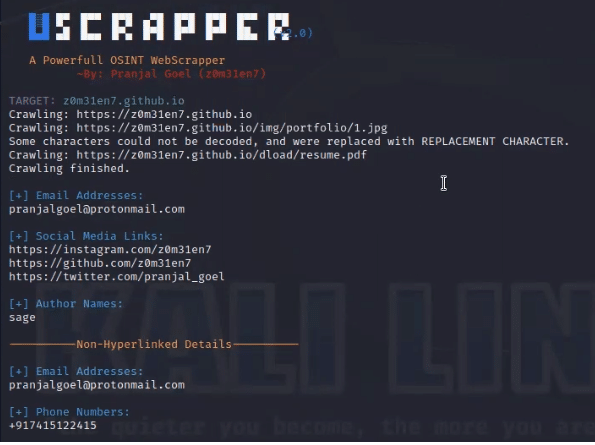
En este apartado te explico cómo realizar web scraping con la herramienta Uscrapper utilizando como «conejillo de indias» la página web https://z0m31en7.github.io/ con un máximo de cinco enlaces a rastrear y con una cantidad de cuatro subprocesos utilizados para el rastreo.
➡️ Te puede interesar: Curso Avanzado de Analista SOCMINT: Inteligencia de Redes Sociales (Nivel 1)


Características de Uscrapper
- Dispositivo: Esta herramienta se puede ejecutar tanto en sistema operativo de Kali Linux, Termux, Windows Terminal o a través de Google Cloud Shell (entorno virtual en la nube).
- Sobre la extracción de datos, Uscrapper extrae los siguientes datos del sitio web proporcionado:
- Direcciones de correo electrónico. Muestra las direcciones de correo electrónico encontradas en el sitio web.
- Enlaces a redes sociales. Muestra enlaces a varias plataformas de medios sociales que se encuentran en el sitio web.
- Nombres de autores. Muestra los nombres de los autores asociados al sitio web.
- Geolocalizaciones. Muestra información de geolocalización asociada al sitio web.
- Detalles no hipervinculados. Es decir, muestra los dominios o subdominios no mostrados en los sitios webs, incluyendo direcciones de correo electrónico, números de teléfono y nombres de usuario.
- Funcionalidades:
- Uscrapper se basa en técnicas de web scraping para extraer información de sitios web.
- La exactitud e integridad de los detalles extraídos dependen de la estructura y el contenido del sitio web que se analiza.
- Para evitar algunos métodos anti-webscraping, utiliza módulos para evitar el bloqueo o límites al obtener la información.
Pasos de instalación de Uscrapper
- Para instalar esta herramienta en nuestro sistema operativo como Kali Linux u otro entorno, debemos de copiar o clonar el repositorio con el siguiente comando:
git clone https://github.com/z0m31en7/Uscrapper
- Una vez copiado este recurso, debemos de ingresar a la carpeta de instalación y proceder a ejecutarla, con estos siguientes pasos:
cd Uscrapper/install/
chmod +x ./install.sh && ./install.sh
- Una vez instalado, podremos ejecutar el programa con esta siguiente línea de comando:
python Uscrapper-v2.0.py z0m31en7.github.io -c5 -t4
A través del anterior comando, le estamos pidiendo a la herramienta Uscrapper que realice web scraping de la página web https://z0m31en7.github.io/ con un máximo de cinco enlaces a rastrear y con una cantidad de cuatro subprocesos utilizados para el rastreo.

Para más información sobre el uso de la herramienta Uscrapper, podéis consultar el siguiente video donde explico y enseño a ejecutar la instalación y ejecución de esta herramienta OSINT:

Nota:
Asegúrese de usarlo de manera responsable y de conformidad con los términos de servicio del sitio web, y las leyes aplicables, respetando siempre los derechos de privacidad de las personas naturales y jurídica y cumpliendo las leyes de protección de datos.
Si te interesa el mundo de la ciberinteligencia, investigación forense y ciberseguridad te invito a formarte en el Curso Avanzado de Analista SOCMINT: Inteligencia de Redes Sociales (Nivel 1) de LISA Institute o seguirme en mis canales donde divulgo sobre cuestiones relacionadas con el OSINT y el SOCMINT:
📌 Mi Página personal: https://manuelbot59.github.io/
📌 Twitter: https://twitter.com/ManuelBot59
📌 Youtube: https://www.youtube.com/@ManuelBot59
📌 LinkedIn: https://www.linkedin.com/in/manuelbot59/
📌 Mi canal en Telegram: https://t.me/OsintManuelBot59
Te puede interesar:




